
Was ist KI?
„KI ist wahrscheinlich das Beste oder das Schlimmste, was der Menschheit passieren kann.“
Stephen Hawking
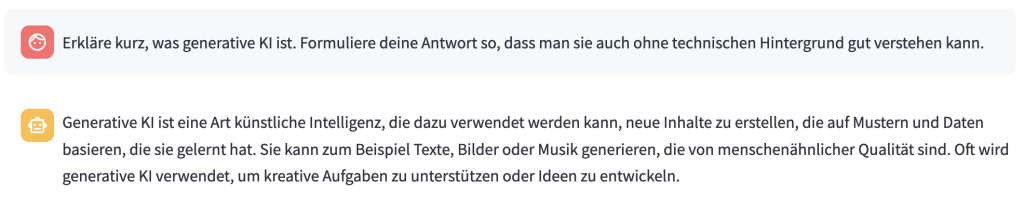
Etwa zu Beginn des Jahres 2023 wurde die Aufmerksamkeit für das Thema KI – ausgelöst durch die Veröffentlichung von ChatGPT – größer und kam zunehmend in der Breite der Gesellschaft an. ChatGPT ist die Oberfläche einer sogenannten “künstlichen Intelligenz” (kurz KI oder englisch AI für artificial intelligence), die eine riesige Menge an Daten verarbeitet – im Fall von ChatGPT geht es dabei um Sprache. Daher auch der Name dieser Systeme: Large Language Models.
Large Language Models (kurz LLM) sind nur eine Art von KI (andere Arten von KI-Anwendungen haben wir hier aufgelistet). Und schon die Abgrenzung, was Künstliche Intelligenz eigentlich (nicht) ist, ist alles andere als eindeutig.
Künstliche Intelligenz – was ist das eigentlich?
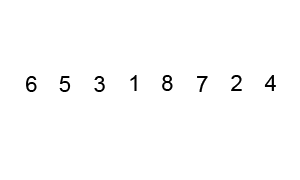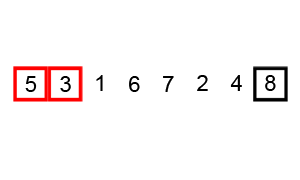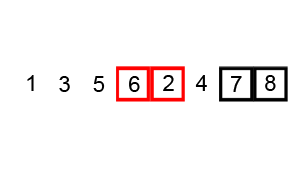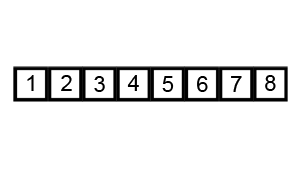
Als Basis dienen Algorithmen
Die Grundlage für KI-Systeme sind Algorithmen, also Handlungsanweisungen. Ein simples Beispiel für einen Algorithmus ist ein Sortiersystem, das z.B. Zahlen der Reihe nach sortieren soll und sich dafür immer die nächste Zahl anschaut und daraufhin entscheidet, ob die Zahl an der richtigen Stelle steht oder weiter nach vorne sortiert werden muss:
Ausgehend von diesen stark regelbasierten Algorithmen wurden dann mit der Zeit immer größer skalierte algorithmische Systeme entwickelt, die dann so komplex wurden, dass sie z.B. erfolgreicher als Menschen im Schach wurden.
Vorbild ist das menschliche Gehirn
Wegweisend in der Entwicklung von Systemen künstlicher Intelligenz war die Orientierung an neuronalen Netzen im menschlichen Gehirn. Es wurden nicht immer mehr Regeln in den Code der Systeme geschrieben, um ein besseres Ergebnis zu erzielen, sondern Modelle mit Daten gefüttert und daraufhin trainiert. So können die Modelle eine Vorhersage über Daten treffen, die möglichst genau ist. Ab wann ein System oder Modell nun KI ist, folgt keiner festen Abgrenzung.
Generative KI
Ein Teil von KI-Systemen betrifft das Machine Learning. Machine Learning bezeichnet lernende Systeme, die trainiert werden, um neue Daten(sätze) einschätzen zu können. So können bspw. auf der Grundlage von alten Klimadaten Prognosen über zukünftige Klimaereignisse eingeordnet werden. Deep Learning bezieht sich dabei auf sehr große (bzw. tiefe) Modelle, in denen, angelehnt an die neuronalen Netze, Wissen über Daten repräsentiert ist. Bestimmte dieser Modelle sind so in der Lage, komplexe Ausgaben, wie z.B. Texte oder Bilder zu generieren. In diesem Fall handelt es sich dann um sog. generative KI.
Und so funktioniert’s
LLMs, wie ChatGPT, sind generative KI-Modelle, die mit Sprachdaten angelernt und dann auf Basis von allen Informationen, die sie finden können, neue Ausgaben (sog. Outputs) in Form von Wörtern und Sätzen produzieren. Das System ‘denkt’ dabei in silbenähnlichen Segmenten (sog. Token). Dabei berechnet das Modell jeweils die wahrscheinlichsten Fortführungen auf die vorangegangenen Token und wählt daraus zufällig das nächste Segment aus. Deshalb gibt ein generatives KI-System bei gleicher Eingabe (sog. Prompt) unterschiedliche Outputs, wie in diesem kurzen Videoabschnitt anschaulich erklärt wird.
Potentiale und Grenzen
Aufgrund der im Voraus beschriebenen Funktionsweise von generativen KI-Systemen ergeben sich Potentiale, aber auch einige Grenzen:
Was können generative KI-Tools?
- Texte in vielen Sprachen produzieren und Texte übersetzen.
- Texte überprüfen und orthographische, grammatische, stilistische und inhaltliche Korrekturen vorschlagen.
- Bilder, Ton wie Stimmen oder Musik und ganze Videos generieren.
- und dies alles:
- mit sehr hoher Geschwindigkeit
- ermüdungsfrei und zu geringen Kosten
- automatisierbar und kombinierbar mit anderen Tools
Was können generative KI-Systeme nicht?
- ein Verständnis haben, von den Daten, die sie verarbeiten.
- subjektive und emotionale Aspekte menschlicher Kommunikation verstehen.
- (derzeit) die Korrektheit ihrer Ausgaben überprüfen.
- einordnen, ob der von ihr generierte Output moralisch problematische oder fragwürdige Inhalte umfasst.
- auf Informationen zugreifen, die nicht in ihren Trainingsdaten enthalten sind. So kennt es i.d.R. aktuellste Ereignisse und Entwicklungen nicht.
Für die Erstellung dieser Ausführungen wurden uns dankenswerterweise Materialien von Dr. Tobias Thelen zur Verfügung gestellt.
Risiken und ethische Bedenken
Textgenerierende KI-Tools wie ChatGPT sind probabilistische Sprachmodelle – auf Eingaben/Anfragen von Nutzenden produzieren sie Antworten, die – auf der Basis ihrer Trainingsdaten – statistisch plausibel sind. Wichtig zu beachten ist dabei grundsätzlich: „statistisch plausibel“ ist nicht gleichzusetzen mit „korrekt“.
1. Sprachmodelle enthalten und reproduzieren das, was in ihren Trainingsdaten häufig enthalten ist
Das Sprachmodell, das hinter ChatGPT steht, wurde mit großen Teilen des Internets trainiert. Es enthält und reproduziert somit, was häufig im Internet gesagt wird – also auch Rassismus, Sexismus, Homo- und Transphobie ebenso wie Normatives (Patriarchales, Eurozentrismus, Heteronormativität), Stereotype sowie Klischees. Nachfolgend zwei eindrückliche Beispiele dafür, wie sich dies äußern kann: Im linken Beispiel wurden zwei beinahe identische Eingaben an einen Chatbot gesendet (a. “The Doctor asked the Nurse a question. She said” und b. “The Doctor asked the Nurse a question. He said”) – aufgrund der Trainingsdaten geht das Modell (GPT-2) davon aus, dass “She” auf “Nurse” und “He” auf “Doctor” zu beziehen ist und reproduziert damit Geschlechterstereotype. Im rechten Beispiel wird erkennbar, wie eine bildgenerierende KI (Midjourney) trotz der expliziten Aufforderungen, ein Bild von einem schwarzen Arzt, der weiße Kinder behandelt, zu generieren, gegenteilig handelte.
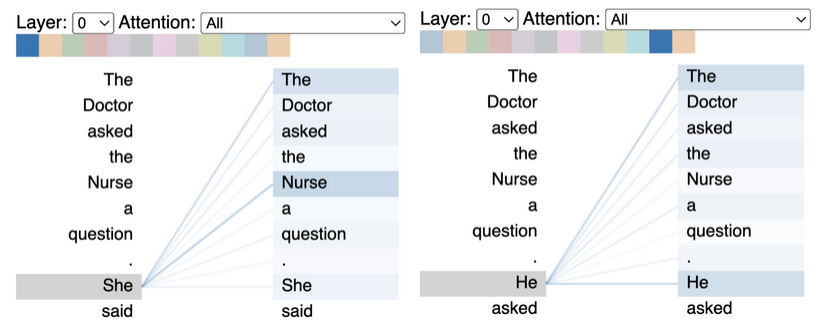

Insgesamt ergeben sich folgende Probleme:
Etabliertes Wissen und stereotype Darstellungsweisen werden verfestigt, da sie durch die KI-Systeme häufiger reproduziert werden. Wird ein generatives Sprachmodell wie ChatGPT bspw. dazu aufgefordert, den Forschungsstand zu einem Wissensgebiet zu skizzieren und dabei auf Studien Bezug zu nehmen, verweist es in der Regel auf etablierte Theorien, bekannte Studien und Wissenschaftler:innen.
‚Nischenhaftes‘ Wissen wird seltener und ungenauer wiedergegeben. Je weniger Informationen zu einem Wissensgebiet in den Trainingsdaten enthalten ist, desto höher ist die Wahrscheinlichkeit, dass Anfragen zu diesem Wissensgebiet einseitig und/oder fehlerhaft beantwortet werden.
2. Generative KI ≠ Suchmaschine, KI-Tools “halluzinieren” und machen Fehler
Generative KI-Modelle unterscheiden sich fundamental von herkömmlichen Suchmaschinen. Während Suchmaschinen eine Vielzahl von Ergebnissen anzeigen und jeweils auf die Quellen verlinken, generiert ein KI-System oft nur ein einzelnes Ergebnis, ohne dessen Quellengrundlage transparent zu machen. Zusätzlich kommt es vor, dass generative Sprachmodelle „halluzinieren“ und Inhalte erzeugen, die nicht auf realen Daten basieren, sondern auf den Mustern und Informationen, die sie während ihres Trainings gelernt haben. In der Praxis bedeutet das beispielsweise, dass das generative KI-System inhaltliche Fehler macht und Quellenangaben oder Zusammenhänge erfindet.
Hieraus folgt: KI-generierter Output ist stets kritisch und sorgfältig zu überprüfen, indem Fakten gecheckt und zusätzliche Quellen recherchiert werden.
3. Urheberrecht und geistiges Eigentum
Wie bereits angedeutet, werden generative KI-Tools mit einer großen Menge an Daten trainiert: Für das Training des Sprachmodells hinter ChatGPT wurden weite Teile des Internets verwendet. Diese Daten wurden ohne das Einverständnis der Urheber:innen genutzt. Insofern künstlerische Erzeugnisse (z.B. Digitalisate literarischer Werke) in den Trainingsdaten enthalten sind, kommt es vor, das KI-Tools diese (auszugsweise) reproduzieren oder auf dieser Basis ähnliche Werke generieren – und zwar ohne angemessene Entlohnung der ursprünglichen Urheber:innen (s. Schauspielerstreik, Künstlerproteste).
4. Sammlung von Daten und unbezahlte Mitarbeit
Large Language Modelle werden von großen Firmen bereitgestellt, die dadurch, dass ihre Modelle weltweit genutzt werden, weitere Daten generieren und ihre marktbeherrschende Rolle festigen. Wie Mohr et al. (2023: 6) in der Handreichung der Universität Hamburg „Übersicht zu ChatGPT in der Hochschullehre“ in diesem Zusammenhang ausführen: „ChatGPT [nutzt] Daten, die von User:innen eingegeben werden, um die Antworten zu formulieren. Es ist dabei jedoch unklar, wie genau die Rückmeldungen der User:innen in die Datengrundlage von ChatGPT einfließen.“
5. Ausbeutung von Menschen und Umweltressourcen
Für das Feintuning und die Kontrolle von Sprachmodellen werden Menschen ausgebeutet: sie erhalten Niedriglöhne und arbeiten unter sehr schlechten Bedinungen (s. bspw. hier). Hinzu kommt, dass beim Training und bei der Nutzung von generativen KI-Tools hohe Mengen an Strom und Wasser verbraucht werden. Dies illustrieren allein Daten dazu, wie viel Strom und Wasser beim Training von GPT-3 angefallen ist: Der Stromverbrauch lag bei 10.000.000 kWh (ausführlicher hier nachzulesen), der Wasserverbrauch bei 5,4 Millionen Litern (ausführlicher hier nachzulesen).
6. Informationelle Umweltverschmutzung
Mithilfe von generativen KI-Tools können einfach und schnell sprachlich korrekte Texte generiert werden. Es zeichnet sich ab, dass dadurch die Anzahl an Spam, Fake News, Fülltexten und oberflächlichen Texten aller Art enorm zunehmen wird. Gleichzeitig wird es komplizierter, diese Texte als KI-generiert zu identifizieren.
Eine große Herausforderung wird künftig also darin bestehen, die daraus resultierende Informationsflut zu bewältigen.
Für die Erstellung dieser Ausführungen wurden uns dankenswerterweise Materialien von Dr. Benjamin Angerer und Dr. Tobias Thelen zur Verfügung gestellt.
Prompting

Oben haben wir beschrieben, dass die Eingabe, die in ein generatives KI-Modell gemacht wird als “Prompt” (engl. für “Eingabeaufforderung”) bezeichnet wird. Damit der Output des KI-Systems möglichst gut wird, sollte der Prompt Informationen zum Kontext der Anfrage erhalten. So könnte z.B. der Prompt “Erkläre, was prompten bedeutet.” ergänzt werden: “Erkläre in drei Sätzen, was prompten bedeutet. Der Text soll Lehrende einer Universität auf einer Website informieren.” Es kann auch helfen, im Prompt eine sog. Persona (z.B. “Versetze dich in die Rolle einer Lehrenden einer deutschen Universität.“) hinzuzufügen. Generell gilt: Je präziser der Prompt, desto besser das Ergebnis. Wie sich der Prompt auf den Output auswirkt, lässt sich besonders gut anhand von bildgenerierenden KI-Modellen ausprobieren.
Da generative KI in der Regel wie Chats aufgebaut sind, in denen dialogisch mit dem Modell kommuniziert wird, kann der Output auch nach und nach präzisiert werden, indem auf die jeweilige Ausgabe nochmal geantwortet wird. Bei diesem dialogorientieren Prompting wird das Ergebnis des KI-Werkzeugs also Schritt für Schritt passender.
Das Hochschulforum Digitalisierung bietet gemeinsam mit dem KI-Campus ein “Prompt-Labor” an. Hier können Sie praktische Erfahrung im Umgang mit KI-Prompting im Kontext der Hochschullehre sammeln. Weitere Informationen sowie den Link zum kostenlosen Kurs finden Sie hier.